Expresiones regulares en programación usando Sublime Text

Este es uno de esos artículos que hago para uso propio. A modo de memorádum, pero como lo veo tan valioso lo publico. Y así no beneficiamos todos. En este artículo hablaremos de las muy útiles expresiones regulares. Yo las uso casi a diario para programar. Sublime Text las reconoce y la verdad que a nosotros los programadores nos hace la vida muy fácil.
Tabla de contenidos - Expresiones regulares en programación usando Sublime Text
- ¿Qué es una expresión regular?
- En este caso las comprobaremos usando Sublime Text.
- Buscar sin discriminar contenido con expresiones regulares
- Buscar patrones de letras y números con expresiones regulares
- Buscar sólo colores hexadecimales con expresiones regulares
- Buscar con tildes y eñes con expresiones regulares
- Otras cosas que podemos hacer con expresiones regulares
- Remplazar el código buscado manteniendo intacta la expresión regular
- Tabla de expresiones regulares.
¿Qué es una expresión regular?
Una expresión regular es una secuencia de caracteres que conforma un patrón. Son utilizadas para la búsqueda de patrones de cadenas y operaciones de búsqueda y reemplazo.
También son conocidas como regex o regexp.
Ahora os hablaré de ellas viendo ejemplos de expresiones regulares.
En este caso las comprobaremos usando Sublime Text.
Ahora os voy a hacer un poco de las expresiones regulares de Sublime Text, primero vamos a activarlas activar las expresiones regulares, bien pinchando en el icono de la imagen de abajo o bien con la siguiente combinación de teclas: ⌥ + ⌘ + R (Mac), Alt + R (Windows/Linux).

Buscar sin discriminar contenido con expresiones regulares
(.*)
Busca cualquier cosa, es decir, que si sólo escribes (.*) te seleccionará el documento entero, pero no se trata de eso, se trata de combinarlo el código, por ejemplo: <td(.*) buscaría todo aquello que empezara por <td(.*) y seleccionaría todo el contenido que le siga en esa línea de código.
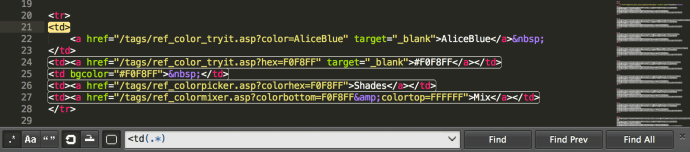
Buscar patrones de letras y números con expresiones regulares
([a-zA-Z0-9#])
Busca cualquier carácter entre el 0 y el 9 y entre la A y la Z, incluyendo mayúsculas y minúsculas y también las almohadillas (#).
([a-zA-Z0-9#])+
Busca cualquier conjunto que combine números, letras o almohadillas. CONJUNTO (gracias al + que significa que ese carácter inicial va seguido de uno o más iguales), con lo que tendremos desde palabras completas a colores en hexadecimal (#7fffd4).
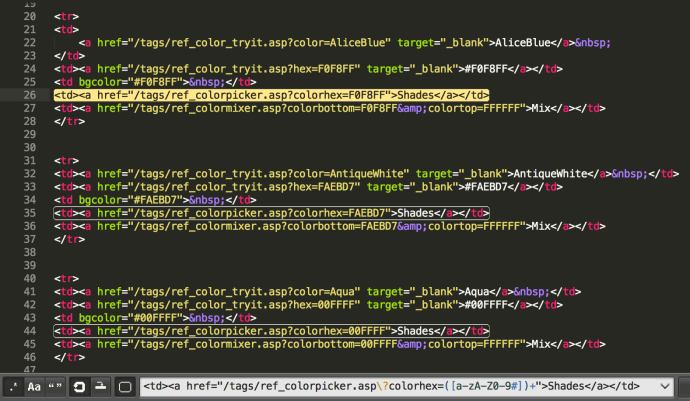
Fijaos en el término de búsqueda, para que funcionara ha sido necesario escapar el signo de interrogación en la url.
Buscar sólo colores hexadecimales con expresiones regulares
(#([a-f0-9]{6}|[a-f0-9]{3}))
La búsqueda sólo devolverá valores hexadecimales (#7fffd4, #fff).

Observad que selecciona los colores precedidos de almohadilla e ignora los que no la llevan.
Buscar con tildes y eñes con expresiones regulares
([a-záéíóúñA-ZÁÉÍÓÚÑ0-9])+
Aquí variamos el patrón de búsqueda para el español, de manera que no ignore las tildes y la ñ.

Queda clara la diferencia entre la selección de cada tipo de patrón.
Otras cosas que podemos hacer con expresiones regulares
Si a un patrón le queremos añadir espacios para que reconozca más allá de la primera palabra, basta con dejar un espacio en blanco tras el 9: ([a-zA-Z0-9 ])+
O, como hemos visto con el patrón español, sumarle toda clase de símbolos que necesitemos: ([a-zA-Z0-9¿?¿¡!.;])+
Como habréis observado el único truco está en emplear los patrones habituales de las expresiones regulares englobándolos con paréntesis, pues es la forma en que Sublime Text y otros editores de código por el estilo lo interpretan. Habéis leído bien, no es una utilidad exclusiva de este programa, pero como es de los más comunes, he preferido hacerlo sobre esta base.
Remplazar el código buscado manteniendo intacta la expresión regular
Ahora toca la siguiente parte del desafío. Una vez tenemos seleccionado lo que queremos remplazar, se nos puede plantear el caso de tener que quitar o modificar la parte estática de la búsqueda, pero respetar la variable (que sería la del patrón que estuviéramos empleando). Entonces, usaremos:
$1
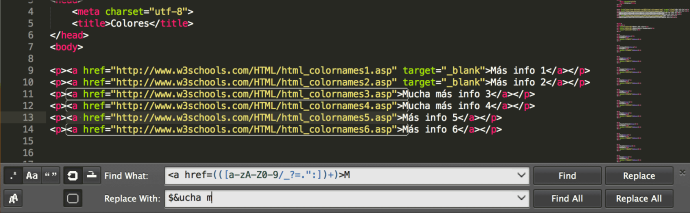
Donde antes escribíamos la expresión regular, ahora insertamos $1. Si os da muchos problemas el remplazo, poned la expresión regular dentro de otro paréntesis: (([a-zA-Z0-9/_?=.":])+) como en la imagen que sigue. Y, por supuesto, si tenemos más de una expresión regular en el campo de búsqueda, iremos sustituyéndolas por $2, $3, $4… representando el orden de aparición.
Ahora bien, si lo único que queremos es añadir algo por delante o al final de todas esas variables, podemos simplemente recurrir a emplear:
$&
Tiramos de comodín para mantener TODA la cadena de datos búsqueda intacta y añadimos el nuevo trozo de código delante o detrás.
Patrones simples de expresiones regulares
Los patrones simples se construyen con caracteres para los que se desea una coincidencia exacta. Por ejemplo, el patrón /abc/ coincidirá sólo con esta exacta secuencia y orden de caracteres 'abc'. Tal expresión tendría resultados en las cadenas "Hola, ¿conoces tu abc?" y "Los últimos diseños de aviones evolucionaron desde slabcraft." En ambos existe una coincidencia exacta con la subcadena 'abc'. Sin embargo, no habría coincidencia en la cadena 'Nayab calló' debido a que, a pesar de que contiene los caracteres 'a', 'b' y 'c', la secuencia exacta 'abc' nunca aparece.
Patrones de caracteres especiales
Cuando la búsqueda de coincidencias requiere algo más que una coincidencia exacta, como por ejemplo el encontrar una o más 'b', o encontrar espacios en blanco, se incluyen en el patrón caracteres especiales. Por ejemplo, el patrón /ab*c/ coincidirá con cualquier secuencia de caracteres en la cual una 'a' preceda a cero o más 'b' (* significa 0 o más ocurrencias del elemento precedente) y sea inmediatamente seguida por una 'c'. En la cadena 'cbbabbbbcdebc,' el patrón coincidirá con la subcadena 'abbbbc'.
La siguiente tabla ofrece una lista completa de los caracteres especiales que pueden utilizarse en las expresiones regulares.
Tabla de expresiones regulares.
| Comando | Significado |
|---|---|
\ |
Buscará coincidencias conforme a las siguientes reglas: |
^ |
Coincide con el principio de la entrada. Si el interruptor o bandera de multilínea está activada, también coincidirá inmediatamente después de un salto de línea. Por ejemplo, /^A/ no coincide con la 'A' en "an A", pero sí con la 'A' en "An E".El carácter ' ^' tiene un significado diferente cuando aparece como el primer carácter en un patrón tipo conjunto o grupo. Véase patrones complementarios para mayores detalles y ejemplos. |
$ |
Busca el final de la entrada. Si interruptor o bandera de multilínea se establece en Por ejemplo, la expresión |
* |
Busca el carácter precedente 0 (cero) o más veces. Es equivalente a {0,}. Por ejemplo, la expresión |
+ |
Busca el carácter precedente 1 o más veces. Es equivalente a {1,}. Por ejemplo, la expresión |
? |
Busca el carácter precedente 0 (cero) o 1 (una) vez. Es equivalente a {0,1}.Por ejemplo, la expresión /e?le?/ encontrará la subcadena 'el' en la cadena "angel" y la subcadena 'le' en la cadena "abominable" y también el carácter 'l' en la cadena "muslo".Si se utiliza inmediatamente después que cualquiera de los cuantificadores *, +, ?, o {}, hace que el cuantificador no sea expansivo (encontrando la menor cantidad posible de caracteres), en comparación con el valor predeterminado, que sí es expansivo (encontrando tantos caracteres como le sea posible). Por ejemplo, aplicando la expresión /\d+/ a la cadena "123abc" encuentra "123". Pero aplicando la expresión /\d+?/ a la misma cadena, encuentra solamente el carácter "1".También se utiliza en coincidencias previsivas, como se describe en las entradas x(?=y) y x(?!y) de esta tabla. |
. |
(El punto decimal) coincide con cualquier carácter precedente excepto un carácter de nueva línea. Por ejemplo , |
(x) |
Busca 'x' y recuerda la búsqueda, como muestra el siguiente ejemplo. Los paréntesis son llamados paréntesis de captura. |
(?:x) |
Coincide con 'x' pero no recuerda la coincidencia. Los paréntesis son llamados paréntesis no capturadores, y permiten definir subexpresiones para manipular con los operadores de las expresiones regulares.Para mayor información, mira Usando paréntesis mas abajo en este artículo. |
x(?=y) |
Coincide con 'x' sólo si 'x' es seguida por 'y'. Esto se denomina previsión (lookahead, mirar adelante). Por ejemplo, |
x(?!y) |
Coincide con 'x' solo si 'x' no es seguida por 'y'. Es una previsión negativa. Por ejemplo, |
x|y |
Coincide con 'x' o 'y' (si no hay coincidencias para 'x'). Por ejemplo, |
{n} |
Coincide exactamente con n ocurrencias de la expresión. N debe ser un entero positivo. Por ejemplo, /a{2}/ no coincide con la 'a' en "candy," pero si con las a de "caandy," y las 2 primeras a en "caaandy." |
{n,m} |
Donde Por ejemplo, |
[xyz] |
Grupo de caracteres. Este tipo de patrón coincide con cada carácter dentro de los corchetes, incluyendo secuencias de escapado. Caracteres especiales como el punto (.) y el asterisco (*) no son especiales en un grupo, así que no necesitan ser escapados. Puede especificar un rango utilizando un guión, como en el siguiente ejemplo.El patrón [a-d], que equivale a [abcd], coincide con la 'b' en "brisket" y la 'c' in "city". El patrón /[a-z.]+/ y /[\w.]+/ coinciden con toda la cadena "test.i.ng". |
[^xyz] |
Grupo de caracteres negativo. Significa que coincide con cualquier cosa que no esté en los corchetes. Puede especificar rangos. Todo lo que funciona en el grupo de caracteres positivo funciona también aquí. Por ejemplo, |
[\b] |
Coincide con backspace (U+0008). Debe ir entre corchetes. (No confundir con \b.) |
\b |
Coincide con un limite de palabra. Un limite de palabra coincide con la posición entre donde un carácter de palabra no viene precedido o seguido por otro. Nótese que el límite no estará incluido en la coincidencia. En otras palabras, la longitud del limite es cero. (No confundir con Ejemplos: |
\B |
Coincide con un no-limite de palabra. Esto coincide con una posicion donde el anterior y el siguiente carácter son del mismo tipo: ambos son o no son caracteres de palabra. El inicio y el final de una cadena se consideran no palabras. Por ejemplo, |
\cX |
Donde X es un carácter entre A y Z. Coincide con un carácter de control en un string. Por ejemplo, |
\d |
Coincide con un carácter de número. Equivalente a Por ejemplo, |
\D |
Coincide con cualquier carácter no numérico. Equivalente a Por ejemplo, |
\f |
Coincide con un form feed (salto de página) (U+000C). |
\n |
Coincide con un line feed (salto de linea) (U+000A). |
\r |
Coincide con un carriage return (retorno de carro) (U+000D). |
\t |
Coincide con tab (U+0009). |
\v |
Coincide con tab vertical (U+000B). |
\w |
Coincide con cualquier carácter alfanumérico, incluyendo el guión bajo. Equivalente a Por ejemplo, |
\W |
Coincide con todo menos caracteres de palabra. Equivalente a Por ejemplo, |
\n |
Cuando n es un entero positivo, es una referencia hacia alguna subcadena de paréntesis dentro de la misma expresion que coincida con el número (contando los paréntesis izquierdos). Por ejemplo, |
\0 |
Coincide con el carácter NULL (U+0000). No preseda este por otro número, ya que \0<numero> se considera una secuencia octal escapada. |
\xhh |
Coincide con un carácter en exadecimal hh (dos dígitos hexadecimales) |
\uhhhh |
Coincide con un carácter unicode con el código hhhh (cuatro dígitos hexadecimales). |
Escapar la entrada del usuario para que sea tratada como una cadena literal en una expresión regular se puede lograr mediante la sustitución simple:
función escapeRegExp(cadena) {
return cadena.replace(/[.*+?^${}()|[\]\\]/g, '\\$&'); // $& significa la totalidad de la cadena coincidente
}
Pruebas estas expresiones regulares con este tester online -> www.regextester.com
Espero que te haya gustado y te sirva tanto como me ha servido a mí.